
El problema de las alucinaciones
Seguramente te resulta familiar la palabra anglosajona «hallucinations», que hace referencia a las alucinaciones que tienen todos los grandes modelos lingüísticos (LLMs). Las alucinaciones hacen referencia a la información incoherente que genera textualmente el modelo, aunque el texto pueda parecer realista o gramaticalmente correcto, es totalmente ficticio o inexacto.
SARA (Smart AI Resource Assistant for Health) es un proyecto de la organización mundial de la salud ( The World Health Organization ) basado en el modelo GPT-3.5. Este LLM ofrece consejos de salud en ocho idiomas diferentes (24×7), sobre comer bien, dejar de fumar, ayuda con los problemas de estrés, etc. Como sucede con todos los LLMs, respondió a usuarios respuestas falsas con direcciones de clínicas de San Francisco que no existían, y debido a las «alucinaciones» del modelo, la organización mundial de la salud publicó en su web, «SARA no será siempre precisa en sus respuestas«.
Si profundizamos un poco este contexto, es bastante preocupante que millones de personas tengan como autoridad médica a un LLM, con problemas de «alucinaciones«, «y sin ser preciso en sus respuestas«. Un médico o un profesional de la salud, es quién debería ayudar a sus pacientes en sus problemas de salud, porque cada contexto personal es diferente. ¿Qué pretende aquí conseguir la organización mundial de la salud?, porque desde mi punto de vista, ha puesto más foco en la tecnología que en resolver un problema.
Figura 1. S.A.R.A (LLMs de la Organización Mundial de la Salud)
Entre otros ejemplos que existen tenemos el de Air Canadá, que en febrero de este año 2024, su chatbot inventó una política de reembolso que no existía en realidad y también el de un abogado que fue multado por presentar documentos judiciales falsos creados por ChatGPT.
Los grandes modelos lingüísticos (LLMs) son tan buenos en lo que hacen,
que te generan confianza.
A finales del mes de octubre, OpenAI publicó un nuevo benchmark llamado SimpleQA (Simple Way to Evaluate Open-Domain Question Answering Systems), creado por sus investigadores. ¿Pero qué es un benchmark?. Los benchmark son herramientas diseñadas para medir los diferentes modelos lingüísticos y comparar sus capacidades de razonamiento, la resolución de problemas matemáticos, capacidad de traducción a un idioma, etc.
El benchmark SimpleAQ ha sido creado para medir la «calibración» de un LLM, a través de preguntas cortas orientadas a buscar un hecho en concreto, es decir, si el modelo lingüístico realmente sabe lo que sabe, en relación a cualquier temática.
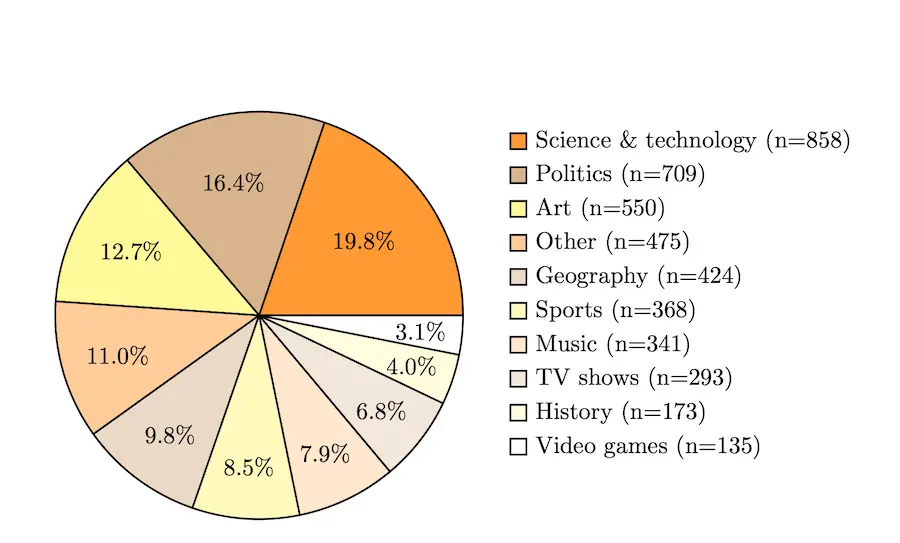
Figura 2. Distribución de temáticas del benchmark SimpleQA.
Cuando realizamos una pregunta a un modelo lingüístico (LLM) (Figura 3), pueden suceder tres cosas: El modelo da una respuesta correcta, el modelo crea una respuesta incorrecta o alucinación y el modelo no responde a la pregunta.
Figura 3. Ejemplos de categorías de clasificación de respuestas del benchmark SimpleQA

Como norma general, un modelo lingüístico responde a tantas preguntas de cualquier temática como sea posible, mientras minimiza el número de respuestas incorrectas. Ahora, con el nuevo punto de referencia creado con el benchmark SimpleQA, OpenAI puede «calibrar» sus propios modelos lingüísticos.
Figura 4. Calibración de los modelos LLMs de OpenAI utilizando el benchmark SimpleQA.
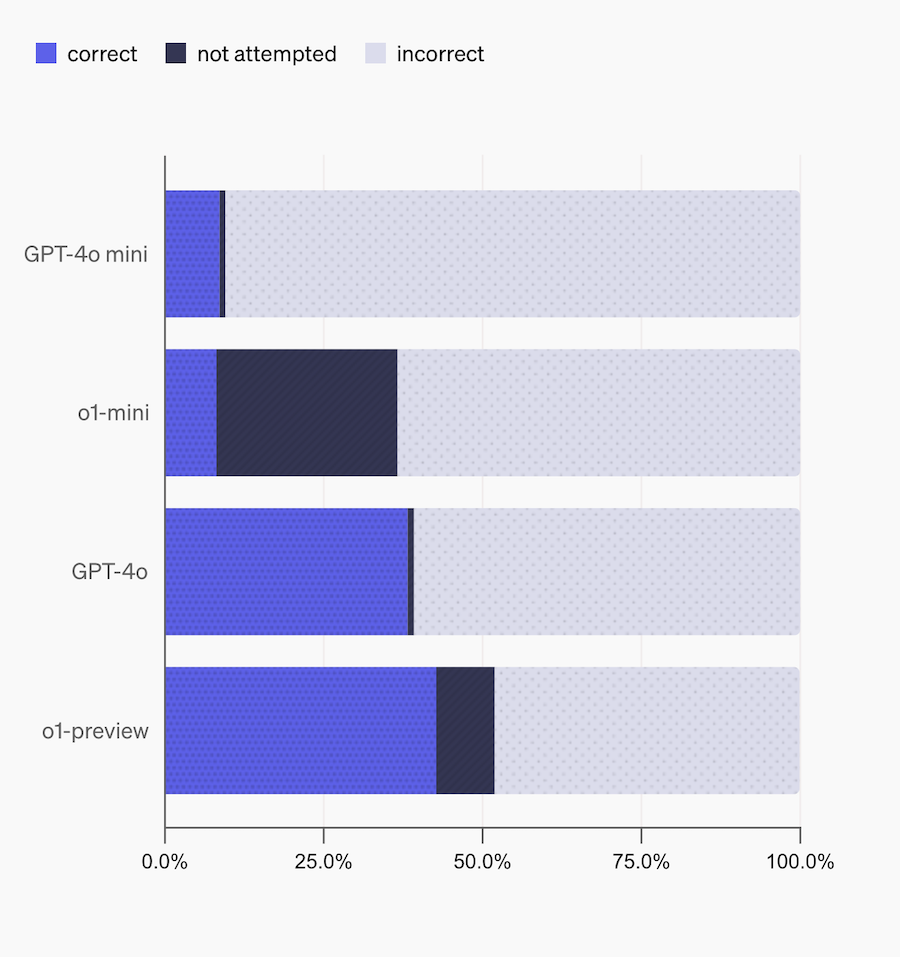
Si observamos el gráfico de la Figura 3, en el 60,8% de los casos, el modelo GTP-4o da la respuesta incorrecta y en el 1% de los casos no responde a la pregunta. Los modelos o1-preview y GPT-4o, tienen un gran conocimiento del mundo al tener un mayor porcentaje de respuestas correctas 38.2% y 42,7%, respectivamente. Sin embargo, los modelos más pequeños o1-mini y GPT-4o mini, al tener menos conocimiento sobre las diferentes temáticas, la probabilidad de responder correctamente es 8,1% y 8,6%, respectivamente.
Creo que es relevante conocer las limitaciones que tienen los LLMs y ser prudentes con el hype que han tenido desde el lanzamiento de ChatGPT, magnificando que podrían responder de forma coherente a cualquier pregunta que le hiciéramos, pero la realidad actualmente, como podemos observar en las investigaciones que están apareciendo sobre las alucinaciones, no es así.