
Razonamiento de los LLMs
El razonamiento de los grandes modelos lingüísticos (LLMs) es un debate interesante. Cuando OpenAI publicó GPT-4o (omni), escribieron en el blog «puede razonar a través del audio, vision y texto en tiempo real». Hace poco publicaron el modelo GPT-o1 y afirmaban que realizaba «razonamientos complejos«, pero ¿qué entendemos por razonamiento?. El razonamiento es la capacidad que tiene el ser humano para estructurar pensamientos e ideas. Incluye capacidades de deducción, inducción, abducción, analogía, reflexión, sentido común y otros métodos <<racionales>> para resolver problemas.
Investigadores de Apple publicaron un «paper» cuestionando la capacidad de razonamiento de los grandes modelos lingüísticos (LLMs) en matemáticas. EL dataset GSM8K (Grade School Math, y 8K es el número de problemas del dataset), es un estándar que ha sido ampliamente utilizado para evaluar en los LLMs el razonamiento matemático a nivel escolar. La mayoría de los LLMs, no saben ignorar la información irrelevante que suele aparecer o se suele añadir al contexto del problema, por este motivo se creó el nuevo dataset GSM-NoOP (Grade School Math – No Operations), para evaluar los LLMs en la resolución de problemas matemáticos, cuando añades información irrelevante.
En el siguiente ejemplo de la Figura 1, se muestra la prueba matemática con el dataset GSM-NoOP, que hicieron a los modelos o1-mini y Llama3-8B. El experimento matemático era el siguiente:
Oliver recoge 44 kiwis el Viernes. El sábado recoge 58 kiwis. El domingo recoge el doble de kiwis que el viernes, pero cinco de ellos eran un poco más pequeños que la media. ¿Cuántos kiwis tiene Oliver?
La frase “cinco de ellos eran un poco más pequeños que la media”, es la información irrelevante que se añade al problema.
Figura 1 Ejemplo del dataset GSM-NoOp, que ha sido diseñado para desafiar las capacidades de razonamiento de los LLMs,
añadiendo al problema matemático información irrelevante.

Como vemos los resultados de los dos modelos devuelven 185 kiwis. Cuando la solución lógica sería 44 + 58 + (44 * 2) = 190. Estos sesgos son desarrollados por el propio LLLM, debido al conjunto de datos de operaciones matemáticas que ha aprendido durante su entrenamiento.
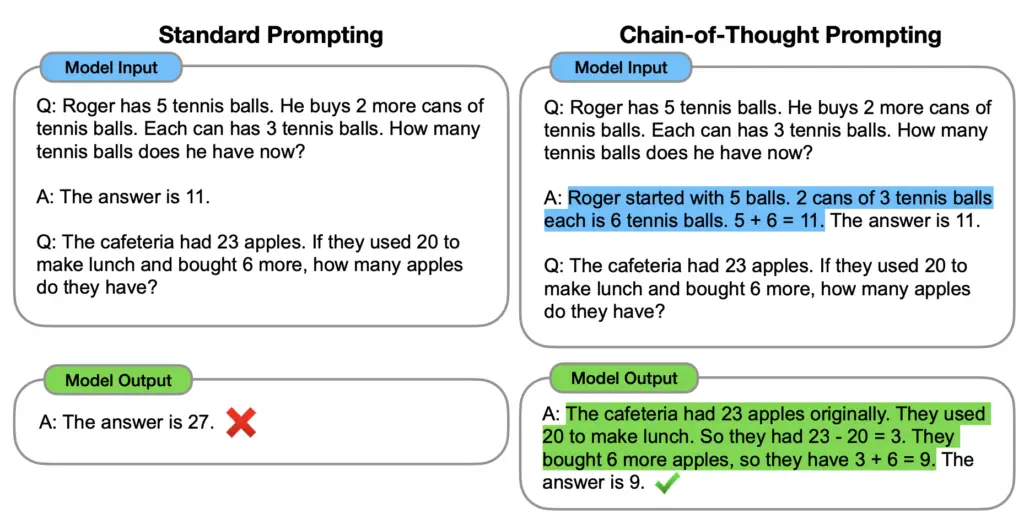
Investigadores del equipo de Google Brain, exploraron la forma de generar una cadena de pensamiento (Chain of Thought, CoT – serie de pasos de razonamientos intermedios) para mejorar la habilidad de realizar razonamientos complejos en los grandes modelos lingüísticos (LLMs). Probaron el método CoT, en conjuntos de datos de problemas matemáticos, problemas de razonamiento de sentido común y otros dominios, y comprobaron que mejoraba notablemente el rendimiento de los grandes modelos lingüísticos (LLMs) en esos conjuntos de datos.
Figura 2 Chain-of-Thought (CoT) permite a los grandes modelos lingüísticos
abordar tareas aritméticas complejas.
Aún así, persisten los debates sobre la técnica «Chain-of-Thought» (CoT). Investigadores de la Universidad de Princeton y la Universidad de Yale, publicaron un «paper» para descifrar los factores que influyen en la cadena de pensamiento (CoT) de un LLM (probabilidad, memorización y razonamiento ruidoso) analizando resultados de los modelos GPT-4, Claude 3 y Llama 3.1.
El estudio demuestra cuatro posibles factores que afectan al rendimiento de la técnica «Chain-of-Thought» (CoT) para que los grandes modelos lingüísticos (LLMs) «razonen».
- Memorización. Repite patrones de razonamiento memorizados a partir de datos de entrenamiento.
- Razonamiento probabilístico. El modelo elige la salida que es más probable, en función de la secuencia de tokens aprendidas durante el entrenamiento.
- Razonamiento simbólico. El modelo utiliza reglas deterministas que trabajan para cualquier entrada, aplicando reglas de inferencia del tipo «si P implica Q y P es verdadero, entonces Q es verdadero», etc.
- Razonamiento ruidoso. Es como el razonamiento simbólico, pero con la probabilidad de cometer un error en cada operación intermedia en un paso de razonamiento.
Como conclusion, hay un consenso entre investigadores que explican que los grandes modelos lingüísticos no entienden realmente los problemas, lo que hacen es replicar patrones en relación a sus datos de entrenamiento o su capacidad de razonamiento probabilístico o simbólico. También puedes encontrar a otros grupos de investigadores que explican todo lo contrario.
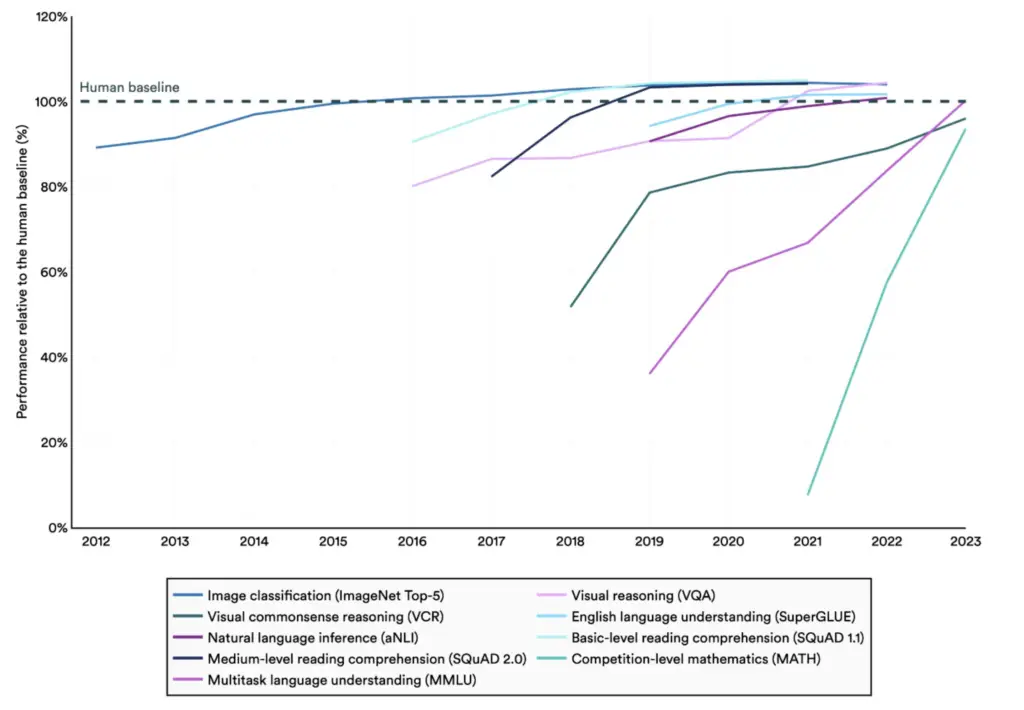
Aunque hay muchas evidencias para que un gran modelo lingüístico no está razonando, sería conveniente tener precaución con las expectativas que existen sobre los grandes modelos lingüísticos (LLMs) en superar a la inteligencia humana (Figura 3), y tener claro como mínimo su funcionamiento, como sus limitaciones.
Figura 3 Rendimiento de modelos que superan a la inteligencia humana
Tenemos un gran debate encima de la mesa en relación con los grandes modelos lingüísticos (Large Language Models). ¿Tu crees que los LLMs razonan como nosotros?